

For finance and operations professionals, absorbing spreadsheets is essential for automation. In this article, we will demonstrate the simplicity of this process within Dataiku, with a specific focus on consuming multiple Excel files as if they were one data source.
For the steps detailed here, ensure your Excel files are accessible on the Dataiku platform. This is typically facilitated by linking to cloud storage solutions, such as Amazon S3, Azure Blob Storage, or Google Cloud Storage. This process also works against FTP and file server locations. Alternatively, users might opt to store files directly within the Dataiku file system.
For the purposes of this blog post, the files are hosted within an Amazon S3 bucket.
Understanding the Business Scenario: Using Amazon S3 for Data Storage
We are part of an organization utilizing Amazon S3 for cloud storage. Our Data Engineering team has crafted a pipeline to transfer daily sales data from a proprietary platform to this cloud storage. Each day’s file has a unique timestamp. Sound familiar?
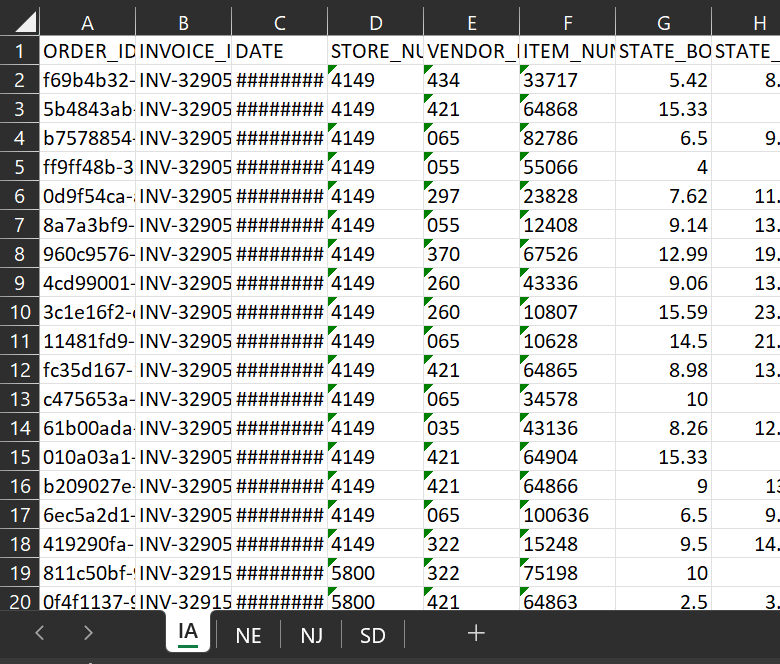
Within each Excel file, we break down sales into different tabs, one for each state we operate in.
The sales team aims to consolidate all these files and sheets to give the executive team a holistic view of organizational sales.
Let’s explore achieving this in Dataiku.
Step-by-Step Guide to Initial Configuration in Dataiku
In our blank canvas, we will select the shortcut ‘Import your first dataset.’
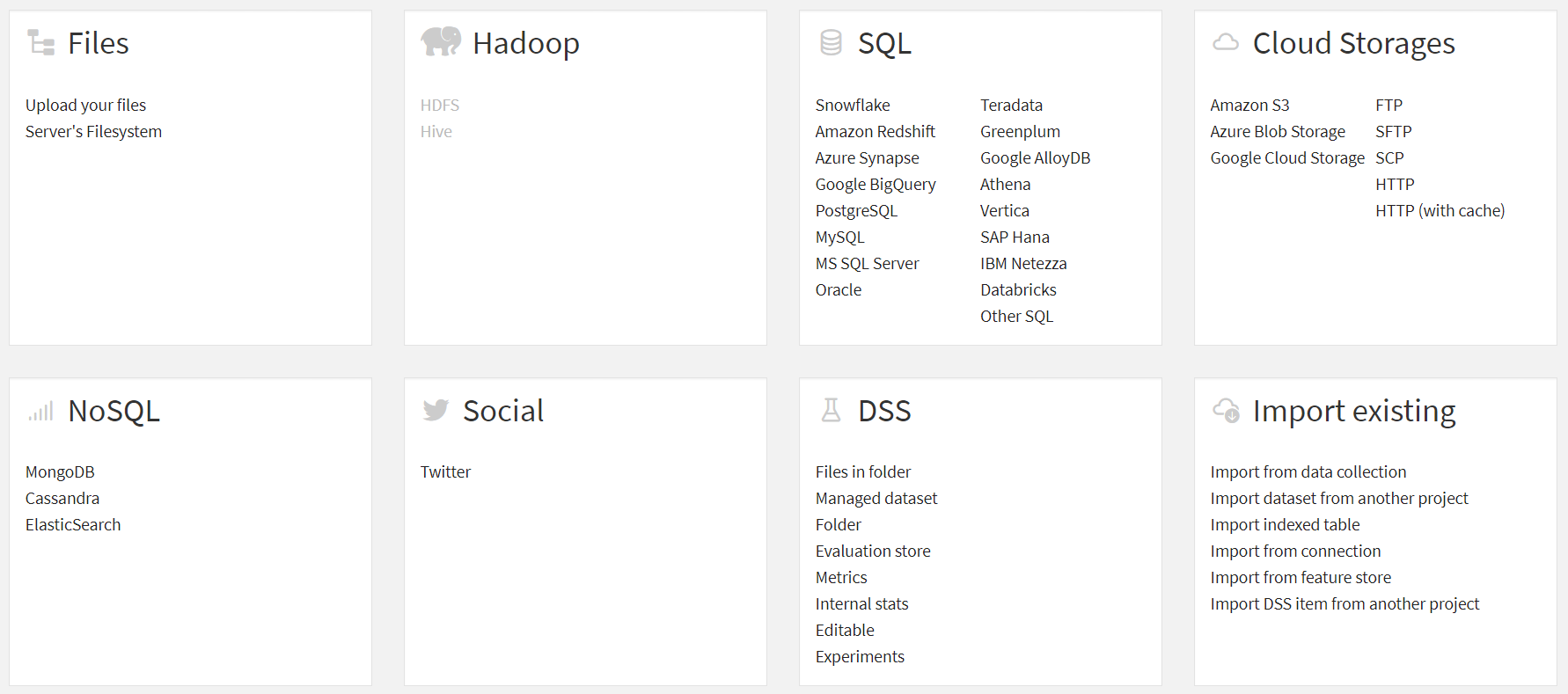
From here, pick the dataset relevant to your files, in our case, ‘Amazon S3.’ Note that the upcoming demonstration applies to other datasets like ‘Azure Blob Storage,’ ‘Google Cloud Storage,’ and more.
Upon selection, a configuration window appears, which is a view similar to that shown below will be displayed.
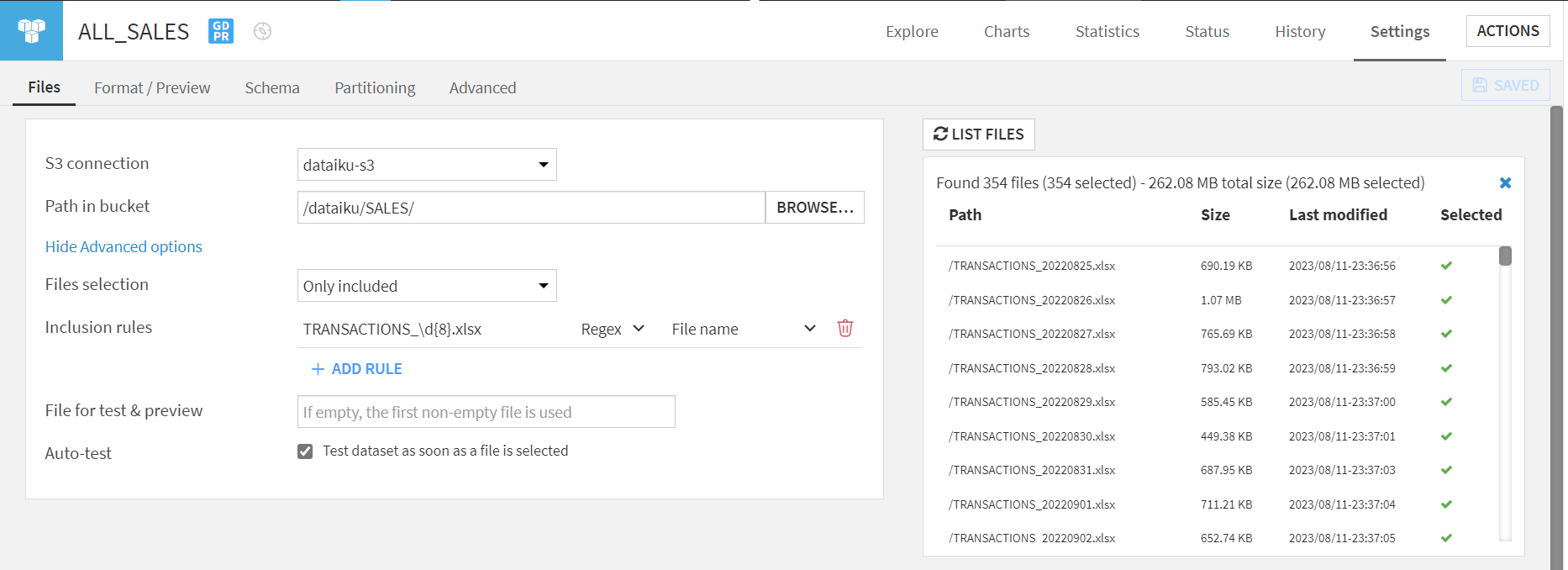
First, determine your connection. For us, it’s the ‘S3 connection’ as we’re linking with Amazon S3. Specify the path to your files. In our instance, they’re under the ‘SALES’ sub-folder.
Next, we must enter the path within the storage environment where our files are stored. You can leave this empty; however, in our case, all of the files are stored within a ‘SALES’ sub-folder. The ‘BROWSE…’ allows you to view the folder structure and content available based on the connections in use.
By default, Dataiku reads all files in the given path. ‘LIST FILES’ lets users see the intended files for extraction.
The ‘Show Advanced options’ provides more specific file selections:
- All – The default choice.
- Explicitly select files – Manually pick files.
- All but excluded – Omit files with a specific naming pattern.
- Only included – Only consider files with a specific naming pattern.
We’ll use the ‘Only included’ mode to fortify our procedure, enforcing a ‘Regex’ rule (e.g., TRANSACTIONS_yyyymmdd.xlsx).
With the ‘Files’ tab configured, proceed to the ‘Format/Preview’ tab to designate the file type and configurations.
Given we’re using xlsx files, ensure that’s selected. To extract data, several methods are provided. We’ll use the ‘By pattern’ option for robustness.
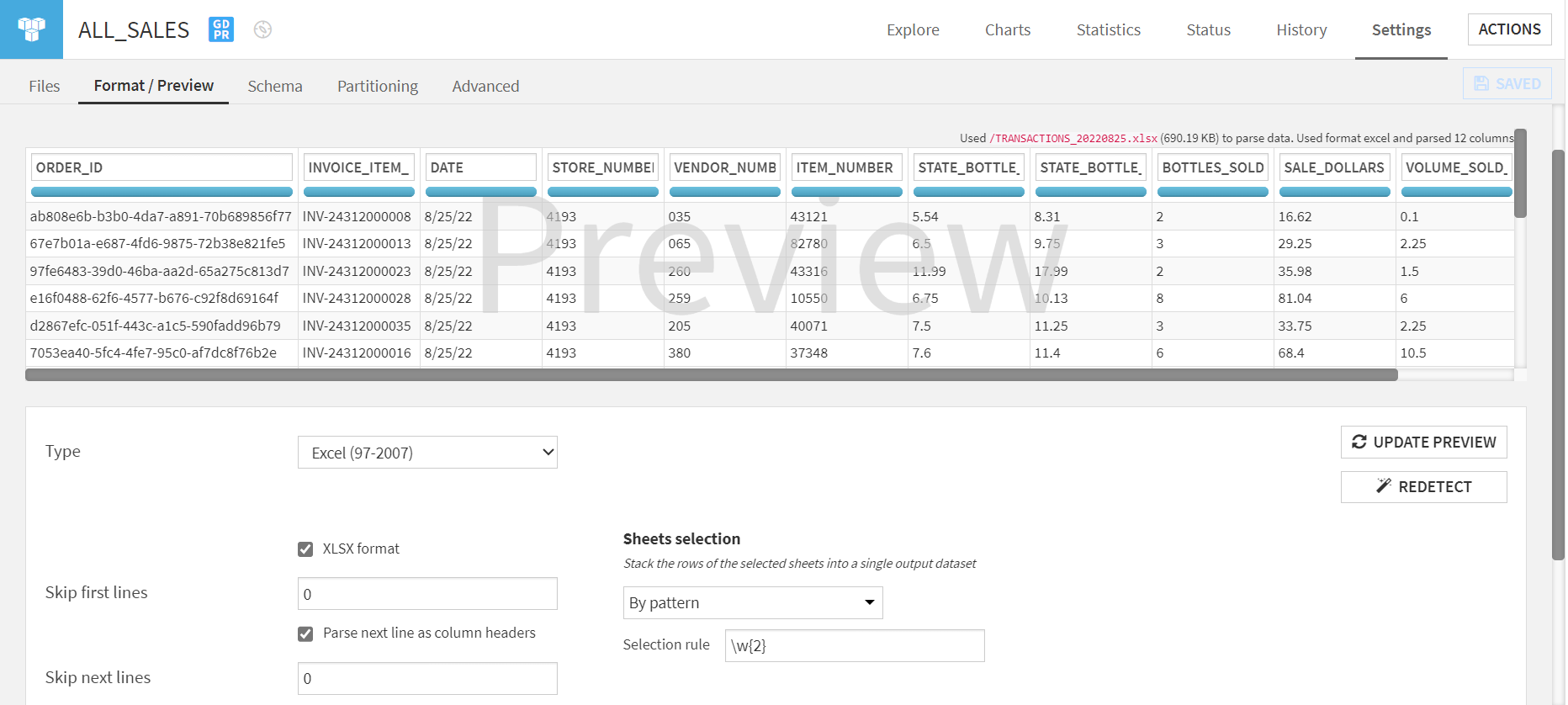
You can now establish your dataset and start your analysis.
Managing Schema Drift in Dataiku: What You Need to Know
When importing multiple files, consider how Dataiku manages schema discrepancies. We conducted tests to examine this, discovering that Dataiku didn’t produce errors; it’s vital that fields maintain a consistent order and append them to the dataset’s right if new fields emerge. For anticipated absent fields, create but leave them vacant.
Leveraging Data Partitioning Features in Dataiku
Partitioning in Dataiku is a feature that enables users to compute groups of data independently from one another.
Initiate this via the ‘Partitioning’ tab, enabling partition creation based on filename date components.
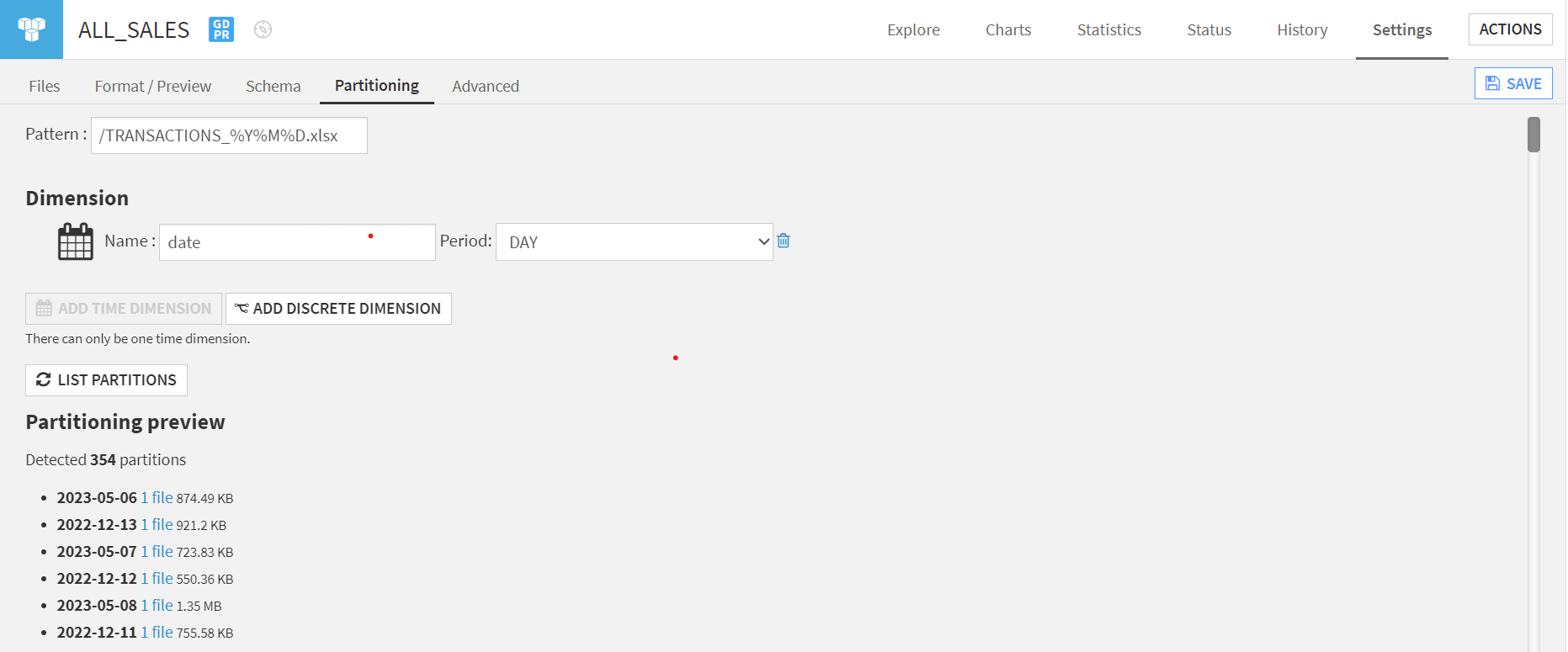
This is advantageous as it allows processing only the latest files, reducing computational demands, and will also significantly reduce the computation required by our Dataiku flow!
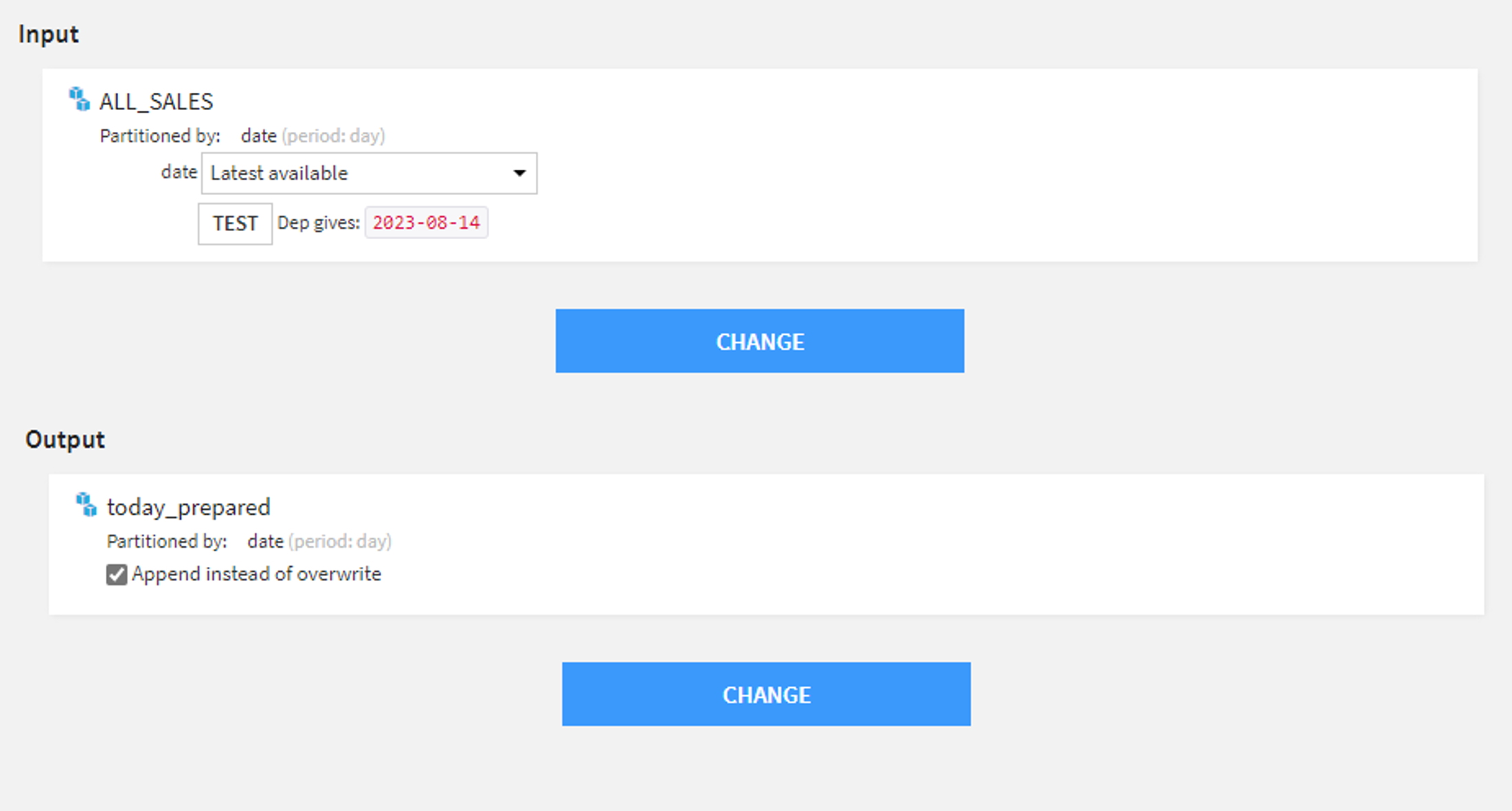
The above image highlights how simple it is to configure your recipe inputs to use the ‘Latest available’ partition. With the output select, we wish to append our transformed data to our output table for consumption by the business.
If your filenames do not contain the required information to build your partitions, then the ‘Partition redispatch’ feature can create partitions based on dataset field values. Check out this article for partitioning file-based datasets.
Get Expert Assistance for Your Dataiku Challenges
We understand that setting this up for each use case is different, and the experts at Aimpoint Digital would be happy to discuss how to set this up for your particular challenge. In some cases, such as pulling the last file based on a modified date, that requires a custom plugin, which we also have experience building. Please reach out to us using the form below.
Author

.png)
